Abstract
Self-supervised learning (SSL) via Masked Image Modeling (MIM) objectives have become a popular source for strong, generalized vision backbones. However, there are key issues with artifacts and noise in the representations learned models that rely on MIM-based objectives.
We present a novel method to measure the amount of non-semantic noise in ViT tokens for state-of- the-art MIM-based models. We characterize non-semantic noise as components that are invariant to the semantic content in the input. This can for example be positional encoding, which are necessary for attention mechanisms but seldom useful in inference, or structural artifacts.
We discover that strong principal components exhibit high levels of non-semantic noise, and that this feature is pervasive in MIM-based models while nearly non-existent in other, non MIM-based SSL models. Importantly, this holds regardless of which positional embedding method is employed and whether predictions are conducted in latent or input-space, suggesting that this is an implicit issue in MIM.
To suppress non-semantic information, we introduce a Semantically Orthogonal Artifact Projection (SOAP) to remove unwanted artifacts that are not useful for inherently semantic tasks, such as instance level classification and salient segmentation—cf. Fig. 1. SOAP is flexible: It is computed directly from data using a Gram-Schmidt based projection, thus requiring no training, and can be attached as an external module to any pretrained SSL backbone.
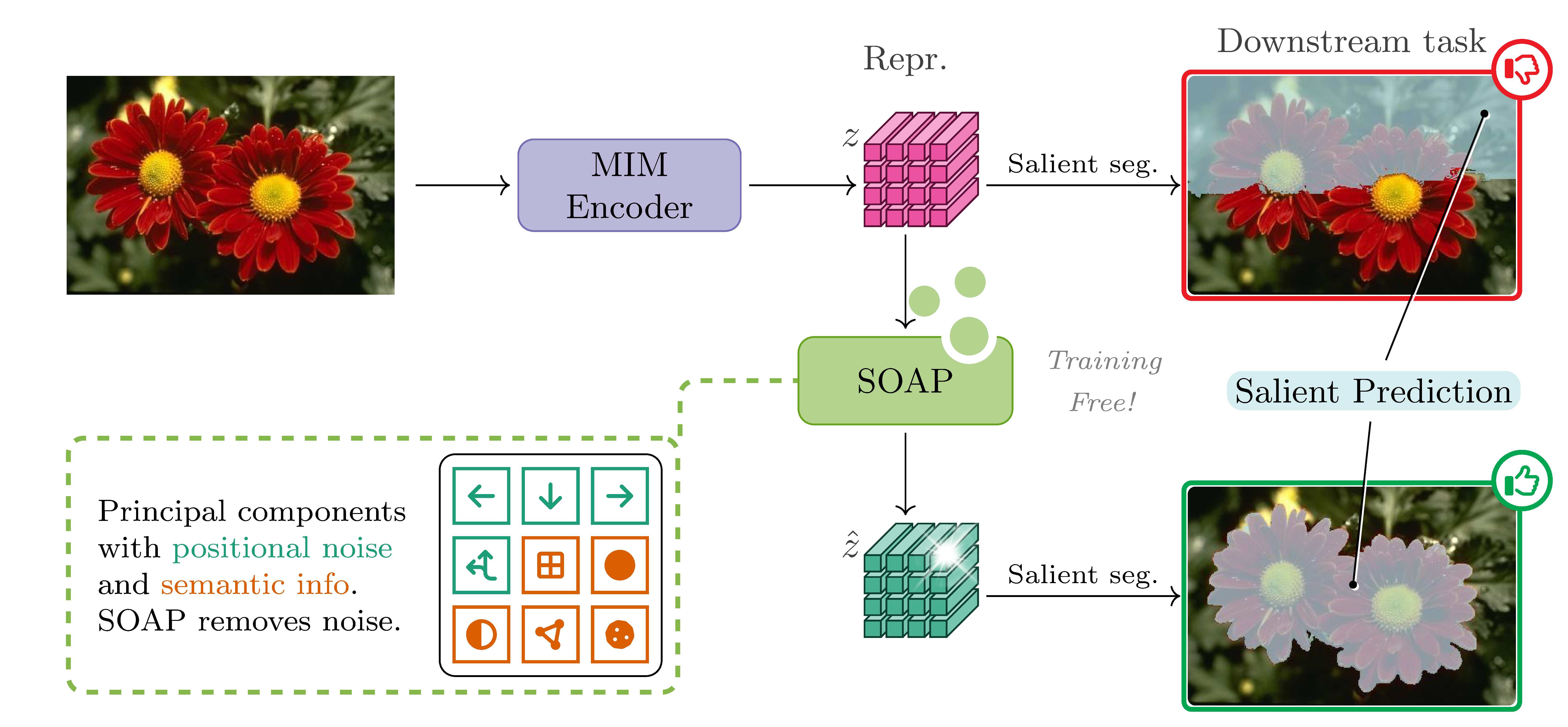
Figure 1: Pipeline overview; a pretrained MIM encoder outputs dense representations zwhich are used for downstream tasks—we show salient segmentation as an example. By identifying and suppressing principal components encoding positional noise, our SOAP module improves the representations and enhances downstream performance in zero-shot settings.
Methodology: The TL;DR
Semantic invariance refers to the property of a component yielding consistent responses even when the semantic content of local representations varies. In other words, a component is semantically invariant if it produces similar activations regardless of whether the input carries meaningful semantic information.
We introduce a new score for measuring Semantic Invariance (SI) in the learned patch representation space, by comparing the representations of real images to those of synthetically generated “noise” images. The synthetic images are generated by a mixture of pink noise, modulated white noise, and random low-frequency gradient fields.
In short, given a model $f$ that encodes an image $x$ into into $N$ patch embedding representations $z_1,…,z_N$, we perform PCA of the patch representation space using Welford’s algorithm to estimate the covariance, and obtain the eigendecomposision $\text{Cov}(\mathcal{Z}) = V\Lambda V^\top \in \mathbb{R}^{D \times D}$, with principal component vectors $V=(v_1, …, v_D)$. Let $\Omega$ be the set of images with natural spatial frequency spectrum. For each principal component we calculate the aggrated activations of real and synthetic images by
\[P_d= \text{mean} \big[ \text{Pr}(A_{d,n}=1 \, | \, x \sim \mathcal{X}) \big], \,\quad \text{where } \mathcal{X} \subset \Omega \text{ is the set of semantically informative images}\] \[Q_d= \text{mean} \big[ \text{Pr}(A_{d,n}=1 \, | \, x^c \sim \mathcal{X^c}) \big], \, \text{where } \mathcal{X}^c \subset \Omega \text{ is the set of images without semantic content}\]where $A_{d,n} = \mathbf{1}[ z_n v_d \geq 0 ]$ is the activation of patch $z_n$ for component $v_d$. In practice, $\mathcal{X}$ can be instantiated as a set of natural images (for example ImageNet validation), while $\mathcal{X}^c$ is approximated by our synthetic image generator. The Semantic Invariance (SI) of component $d$ is then measured by
\[s_d = 2 \cdot \frac{P_d \cdot Q_d + (1-P_d)\cdot(1-Q_d)}{\sqrt{P_d^2 + (1-P_d)^2} + \sqrt{Q_d^2 + (1-Q_d)^2}} = 2 \cdot \frac{ \langle {P}_d, {Q}_d \rangle}{||{P}_d|| + ||{Q}_d||},\]which assigns high scores when $P_d \approx Q_d$, and vice versa.
Finally, we introduce Semantically Orthogonal Artifact Projection (SOAP), a simple Gram-Schmidt-based post-hoc projection method to suppress components with high SI score:
\[P_\phi = I - VWV^\top, \quad W=\text{diag} (w_1,...,w_D) \quad \text{s.t.} \quad w_d = s_d \times \frac{ \sigma (\mu - r)/ \tau}{\sigma (\mu/ \tau)}; \quad r = \text{rank}(s_d).\]Here, $\mu$ and $\tau$ are hyperparameters to control the cutoff and smoothness of suppression. This projection can be used to “correct” the patch representations $\hat z = P_\phi z$ by removing the contribution of components that encode non-semantic information such as positional noise.
Read our paper for a more in-depth formulation and explanation of the methodology!
Semantic Invariance in MIM models
We analyze popular SSL models by measuring their Semantic Invariance, and find a striking contrast between models trained with and without a MIM-style objective. The main findings are summarized by the plots below. Models with MIM are shown in solid lines; models without MIM are shown in dashed lines.
Figure 2: Semantic invariance (SI) score in descending order. All scores are shown in the left plot, while the right focuses on the top 10 semantically invariant scores.
The models trained with MIM have at least two principal components with high SI score ($\geq 0.75$). Upon manual inspection, we find that these components encode positional infomation about the patch location. Critically, DINO and DeiT3, which are not trained with MIM, do not exhibit the same behaviour and have lower SI scores in general ($\leq 0.75$).
Looking at the maxumim SI score of each transformer block, we see that while some MIM-models (DINOv2 and DINOv3) have lower SI scores in earlier layers, there is a sharp increase in the last layers, where all MIM-models land well above the $0.75$ threshold. This can be explained as the model saturating more positional information into the embeddings in preparation for solving the MIM task.
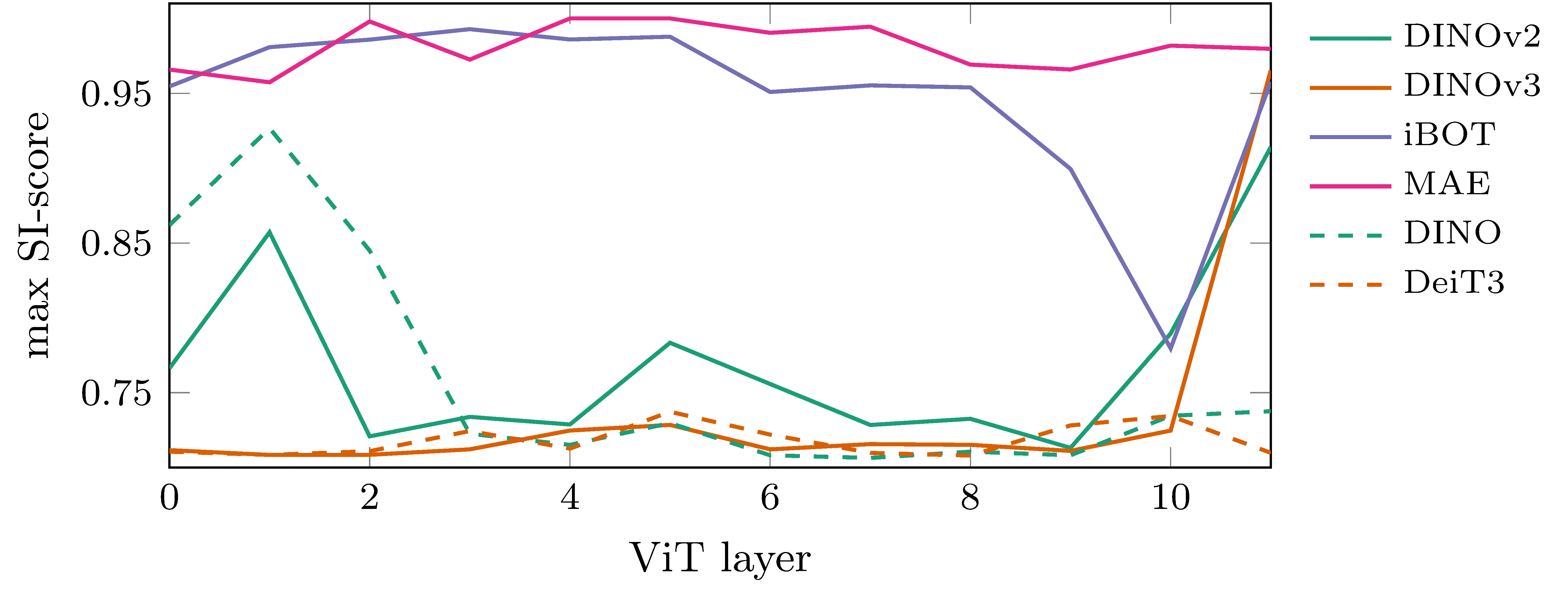
Figure 3: Maximum semantic invariance score for MIM models (solid lines) and non-MIM models (dashed lines) vs. model depth. Critically, MIM models show high SI-scores in the last layers. This can be explained by the MIM objective encouraging positional information in the patch embeddings of deeper layers.
SOAP improves zero-shot performance
We use SOAP to correct for semantically invariant components in local embeddings, and find that this improves performance in zero-shot downstream tasks for all MIM models in our study. Read our paper for more results!
Salient segmentation
We use TokenCut for zero-shot evaluation of salient information present in patch embeddings, and find that correcting with SOAP can significantly improve performance. Below are the results for the ECSSD dataset.
| Pretrain | Model | max Fβ | IoU | Acc |
|---|---|---|---|---|
| Original embeddings | ||||
| DINO | ViT-B16 | 82.580 | 74.325 | 90.929 |
| DINOv2 | ViT-B16 | 71.319 | 63.937 | 83.147 |
| DINOv3 | ViT-B16 | 36.975 | 29.122 | 52.953 |
| iBOT | ViT-B16 | 62.873 | 56.248 | 78.785 |
| CAPI | ViT-L14 | 72.456 | 66.083 | 84.334 |
| MAE | ViT-B16 | 79.952 | 71.067 | 89.410 |
| I-JEPA | ViT-H14 | 37.670 | 27.989 | 68.898 |
| SOAP corrected embeddings | ||||
| DINOv2 | ViT-B16 | 80.633 | 72.559 | 88.687 |
| DINOv3 | ViT-B16 | 42.633 | 33.742 | 61.975 |
| iBOT | ViT-B16 | 66.557 | 60.167 | 78.340 |
| CAPI | ViT-L14 | 85.219 | 78.084 | 92.600 |
| MAE | ViT-B16 | 82.094 | 72.118 | 91.444 |
| I-JEPA | ViT-H14 | 40.239 | 31.162 | 71.406 |
kNN segmentation
We evaluate zero-shot segmentation on ADE20k by performing per-patch k-nearest neighbors (kNN) and upsampling the predictions to full image resolution using nearest neighbor interpolation.
| Pretrain | Model | IoU (Org.) | Acc (Org.) | IoU (SOAP) | Δ IoU | Acc (SOAP) | Δ Acc |
|---|---|---|---|---|---|---|---|
| DINOv2 | ViT-B16 | 40.253 | 74.603 | 40.808 | ↑ 0.556 | 74.723 | ↑ 0.120 |
| DINOv3 | ViT-B16 | 43.849 | 77.943 | 44.575 | ↑ 0.725 | 78.101 | ↑ 0.158 |
| iBOT | ViT-B16 | 27.726 | 70.859 | 28.426 | ↑ 0.700 | 71.262 | ↑ 0.403 |
| CAPI | ViT-L14 | 31.382 | 71.626 | 31.637 | ↑ 0.255 | 71.770 | ↑ 0.144 |
| MAE | ViT-B16 | 11.882 | 58.002 | 12.651 | ↑ 0.769 | 58.592 | ↑ 0.591 |
| I-JEPA | ViT-H14 | 20.952 | 60.273 | 21.258 | ↑ 0.306 | 60.287 | ↑ 0.014 |
Citation
@inproceedings{hjelkremtan2025soap,
title={Suppressing Non-Semantic Noise in Masked Image Modeling Representations},
author={Hjelkrem-Tan, Martine and Aasan, Marius and Chakraborty, Rwiddhi and Arteaga, Gabriel Y. and Choi, Changkyu and Ram\'irez Rivera, Ad\'in},
booktitle={IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2026}
}